MMMの課題と展望
はじめに
広告・マーケティング関係の仕事をされている方は、MarketingMixModeling(MMM)という手法を聞いたことがあるのではないでしょうか。重回帰ベースの手法を用いて広告の効果を計測し、よりよい広告出稿プランに繋げるためのソリューションです。
少し前には、Google×博報堂、Google×電通デジタルでMMMのガイドブックが出ていたことや、最近ではGoogleからMeridianという新しいライブラリが公開されたこともあり、ホットな話題に思います。
(Meridianについては下記にまとめています。)
本記事では、Googleさんが出されていた"Challenges and opportunities in media mix modeling" という論文についてまとめていきます。日本語訳すると、「MMMの課題と展望」などでしょうか。名前からして、いかにもMMMの概要・課題・限界がまとまっていそうですね。publishされたのは2017年と、そこまで新しい論文ではないですが、GoogleさんがMMMについてまとめられている論文であれば、読んでおいて損はないでしょう。
MMMに関する基本事項は他にいくらでも参考文献があるので割愛しますが、端的にいうと、「重回帰ベースの手法を用いてマーケティング活動のROIを計測&最適化する手法」です。
MMM自体は分析の概念を示しているので、その際のモデルのアルゴリズムは複数存在し、例えばGoogleのMeridian(やLight weight MMM)は、時系列構造を持たせた回帰モデルをMCMCで推定する手法、MetaのRobynは、Prophetを用いて時系列性を加味しながらRidge回帰で解く手法となっています。
他にも企業や論文によっては、時系列性を加味しない重回帰で解いている事例や、状態空間モデルの枠組みで広告効果を時変係数として(広告効果が時間によって変化することの表現)解いている事例(Ng et al., 2021)もあります。
少し話がそれましたが、以下では、章ごとに論文の内容を整理していきます。
1. Introduction
ここでは、MMMの概要が説明されています。
MMMとは、気温や季節性などのcontrol variableとマーケティング変数を用いて重回帰をすることで、ROASを計測&出稿の最適化を行う、1960年台から利用されている手法です。
具体例を挙げると、①メディアのROAS、②翌年にマーケティング費用を下げた場合の売上、③売上を最大化するためのメディア予算配分、などを算出できる手法として、広告主から指示されています。
一方で、MMMは少サンプルの集計データに対して分析されることが通常であり、分析結果を因果関係とみなすには限られた条件が存在する、ということは1つの問題点として挙げられます。この点を含めて、論文内で解説が進められています。
2. Causal Inference
MMM以外で広告効果を計測する2つのアプローチについて触れています。
①RCT(ランダム化比較実験)
ランダムに分けた2つの同質な集団をtest群/control群に分類し、2つの群のふるまいを観察する方法。
②Potential Outcome(潜在反応アプローチ)
Rubinの因果推論の手法。広告に接触した場合の潜在的結果変数の値から、広告に接触した場合の潜在的結果変数の値を差し引くことで、広告効果を識別することができる旨が記載されています。
(潜在反応モデルのフレームワークとして、Rubin流の欠測データを基調とした因果推論が触れられていました。潜在反応自体は、Pearl流のグラフィカルモデルを基調とした因果推論を用いても構成することができますが、本論文内ではRubin流のみ記載されています。)
上記①②、2つの手法が、現実的でない・実行できない場合に、MMMを用いた分析が利用されます。
3. Regression
MMMの課題と展望について議論するために、分析手法の基礎について振り返ります。
MMM特有の機能として組み込まれる、アドストック(広告の残存効果)と飽和効果(出稿量とKPIの関係が単純な比例関係ではなく、効果が一定で飽和する特性)について触れたうえで、MMMの式が整理されています。(アドストックや飽和効果の一般的な表現についてはこちら)
MMMに利用するデータとしては、下記が挙げられていました。
・目的変数:通常は売上の変数が利用されるが、来店なども可
・メディア変数:imp/click/出稿量/出稿金額など
・マーケティング変数:価格/プロモーション/配荷量など
・control variables:季節性/気候/競合の情報など
さらに、MMMの結果がより信頼性の条件としては、下記が挙げられていました。
・データのサンプルサイズが大きいこと
・それぞれの説明変数の分散が有益であること(≒ 分散が大きいこと、メディアごとに出稿タイミングが異なること)
・説明変数がそれぞれ独立であること(≒ 意訳すると、相関が小さいこと*1。メディアごとの出稿タイミングがずれていることや、その他の説明変数も含めて、マルチコが起きていないこと。)
・モデルが目的変数(KPI)のファクターをすべて説明していること
・モデルがすべての変数間の因果関係を捉えていること(MMMはSEMや複数の重回帰モデルで解くこともあるの)
これらの点は、4章の話にも繋がっていきます。
4. Challenges
ここからが、この論文のメインです。4章では、MMMの問題点について触れられています。
問題提起はしますが、解決策が提示されていない場合も多いので、その点はご了承ください。
データの制約
まずは、データの制約からくる問題点です。
MMMは週次のデータを用いたモデリングが通常であることからサンプルサイズが小さいです。係数の推定精度が下がることで、モデルの信頼性が低下します。
また、マーケティング活動は一度に複数の施策をするのが通常であるため、説明変数間の相関が高くなってマルチコの問題も発生します。
(マルチコとサンプルサイズ、推定精度の関係については下記に書きました)
また、既存データの範囲外の数値に対して表現することができない、いわゆる外挿の問題も発生します。出稿量を変化させた場合のシミュレーションを行うこともMMMの目的の1つにあるので、こちらも大きな問題ですね。
セレクションバイアス
モデルに利用する変数が未観測な変数の影響をうけることにより、正しい推定がうまくされない問題が挙げられています。具体的には、ターゲティング・季節性・ファネル効果、によって、データにバイアスが発生してしまうそうです。
ターゲティングバイアスは、特にデジタル媒体が絡む場合に問題となります。例えば化粧品商材の広告の場合は、「全年代にむけて、TVCMを100万円出稿する場合」と、「ターゲットである20~30代女性に向けて、デジタル広告を100万円出稿する場合」では、明らかに後者の方がROASが高くなりそうですよね。ここではデモグラ特性が交絡因子となって、重回帰分析のモデルのみでは、広告効果を媒体横並びで比較することができなくなってしまいます。
季節性バイアスは、売上に季節的な影響がある商材の場合に問題となります。例えば薬の商材の場合は、風やインフルエンザの流行に伴って、売上が変動します。当然、広告も季節に合わせて打つため、売上の増加が、季節性によるものなのか広告によるものなのか、判別が難しくなってしまうということです。
カテゴリの売上平均値を説明変数として用いることや、アルゴリズムで季節性を捉えることで対処する場合もありますが、これが根底にある需要を正確に反映しているという保証はなく、バイアスが発生してしまう場合があります。
メディアにファネル効果がある場合(各メディアがもつ態度変容ファネルへの影響に差がある場合)にも、バイアスが発生します。例えば、TVCMが検索行動と事業KPIに影響を及ぼし、検索行動から影響を受けた検索広告(出稿量)が、事業KPIに影響を及ぼす場合を考えます。この場合、TVCMと事業KPIの間に、中間変数として、検索広告が入ってしまいます(TVCMが事業KPIに対して間接効果を持っている)。こういった状況では、KPIを目的変数、各メディアを説明変数においた1つの回帰式でMMMを解こうとすると、バイアスが生じる場合があります。
モデル選択と不確実性
モデルをR2乗値で選択するのか、それとも誤差から選択するのか、という点は、明確な答えがありません。
また、同程度の精度をもつモデルが複数でてきた場合に、どちらを信用すれば良いかわからなくなってしまう、という話は、以前TJOさんの記事でも触れられていました。
論文とは話がずれますが、Meta社のオープンソースMMMであるRobynは、MMMの結果を複数出力するようになっています。Robynでは、ハイパーパラメータの推定結果を元にクラスタリングを実行し、異なる傾向をもつモデルを複数出力する構造になっているので、Robynの利用の際にも、モデル選択は大きな問題になりそうですね。
シミュレーション的に、モデル選択が及ぼす不確実性について見てみます。
下図は、同じようなR^2, MAPEをもつ5つのモデルを用いて、予算(x軸)を増加させたときに売上(y軸)がどれだけ増加するかをシミュレーションしたグラフです。
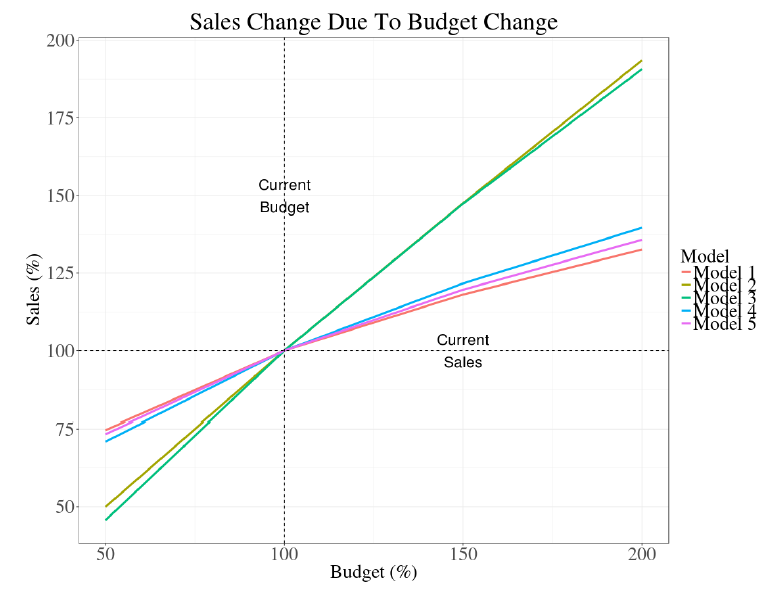
モデルによって、売上のシミュレーション値が大幅にずれてしまっていることが見て取れます。
モデルの評価指標上はどれも妥当なモデルといえますが、選択するモデルによって、売上シミュレーションや最適予算配分の出力が、大きく異なってしまうことがあります。
5. Opportunities
この章では、4章で説明していたような問題をもつMMMについて、より信頼性を高めるためにはどうすれば良いのか、という論点で整理がされています。良いデータ/良いモデル/モデル選択という3つの観点から整理されています。
良いデータというのは、正確なデータ・粒度の高いデータ、です。これは、広告代理店と広告出稿媒体社で綿密な連携を取りながら、MMMに利用するデータを標準化してしまう、ことが重要です。
下記では、良いモデル/モデル選択、について見ていきます。
ベイズ推定
MMMのパラメータ推定には、最小二乗/最尤推定/ベイズ推定など、複数のアプローチが存在しています。本論文では、基本的にはベイズ推定をするのが良いとされています。
ベイズ推定を用いるメリットとして、ビジネス上有益な事前分布を用いることができる点、複雑なモデルを取り扱うことができる点、モデルの信用区間を求めることができる点、などが挙げられています。また、次節で説明するカテゴリ粒度のモデル、とも相性が良いです。
もちろん、実務上、計算コストの問題はありますが、MMMは長期間のマーケティング活動の振り返りという観点から、頻繁に実行することは少ないため、1度のモデリングの計算コストは補いうるでしょう。
カテゴリ粒度のモデル
カテゴリ粒度で事前分布を統一した上で、ブランドごとに推定値を変化させるMMMも提案されており、より柔軟・高度なモデルに拡張することも見越しています。
Googleは、カテゴリ粒度のモデルから得られた情報を、ブランド粒度のモデルに活かすことを推奨しています。(Wang et al., 2017)
具体的には、
①カテゴリ粒度のモデリングした結果をブランド粒度のモデルの事前分布として組み込むやり方や、
②カテゴリ粒度で事前分布を統一した上で、ブランドごとに推定値を変化させる階層ベイズモデル、
が考えられます。これにより、データやデータがもつ情報量の不足を補うことができます。
例えば、コカ・コーラ社のMMMでいうと、①②それぞれ、
①炭酸飲料というカテゴリ全体で一度モデルを作って各パラメータを算出しておいて、コーラ/ファンタ、というブランドレベルのMMMをやる際に、事前分布として組み込んであげる
②コーラ/ファンタなど、炭酸飲料カテゴリを含むデータに対して、それぞれの回帰係数パラメータの事前分布を同一としたうえで、ブランドごとに別々で係数の事後分布の推定値を算出する
というようなイメージです。
Geo models
地域粒度のデータに分類したモデリングにより、サンプルサイズを増加させることができます。
日本であれば、地方ごと、あるいは都道府県ごとのデータを利用することで、その分サンプルサイズが増え、推定したパラメータの分散を小さくすることができます。(Sun et al., 2017)
一方で、地域粒度のデータがすべて集まることは稀である、とも感じています。KPIのデータ、各媒体のデータ、など、すべてを地域粒度で持っている企業さんは少なく、良くて東阪名くらいのレベルではないでしょうか。この辺りは少し、研究領域とビジネス領域のギャップを感じます。
Control variables
検索広告(paid search系メディア)は、検索者に対して出稿されて課金が発生するメディアであるため、検索数(潜在的な需要)の影響を強く受けます。
このとき、検索数の推移という要因が、売上と検索広告の出稿金額の双方に影響を与える共変量として存在しているので、補正をする必要があります。(バイアスを補正する際の共変量の選び方については、以前こちらに書いています。)
Googleでは、検索広告の効果を推定する際に、検索量の値を用いて補正したMMMを実施した事例があります(Chen et al. 2018)。このような補正の考え方は検索広告の補正に限定されるものではなく、他の媒体の効果を推定する際にも考慮すべきだとされています。例えば、リタゲ広告の効果推定の際は、"webサイトの来訪" という値を共変量として用いて補正できる可能性が挙げられています。
グラフィカルモデル
グラフィカルモデルは、challengesの部分で上げていたファネルエフェクトによるバイアスに対する、1つの解決策となるアプローチです。グラフィカルモデルは、未観測の変数も含めた変数間の複雑な相互関係を表現するためのツールです。
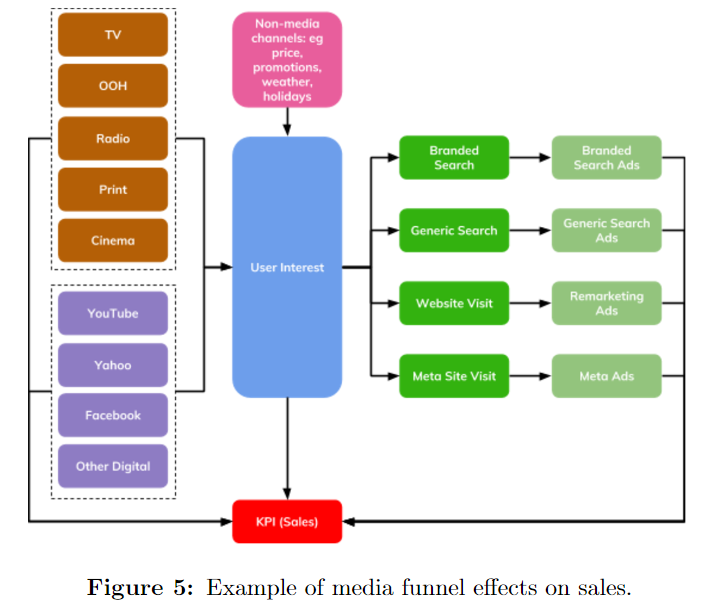
上図のグラフィカルモデルのアプローチにより、通常の重回帰や2段階の重回帰(one-stage or two-stage regression)よりも現実的なモデルを作ることができます。(2段階の重回帰というのは、中間KPIとなるような変数をおき、最終KPIが目的変数の重回帰と中間KPIが目的変数の重回帰、2つの重回帰で解く手法と理解しています)
model validation
異なる仮説の元で、異なるモデルがどの程度正確に動作するかを評価するために、シミュレーションを実施することが提案されています。シミュレーションによってMMMデータセットを作成し、それを正解データとして、MMMがどれだけ正確なものになっているかを検証するということです。
シミュレーションを通して、例えばアドストックの効き方や、メディア変数間の相互関係など、さまざまな仮定のもとにMMMの検証データを作成することができます。
シミュレーションの詳細については、(Zhang & Vaver, 2017)を参照してください。
6. Final remarks
MMMにも限界があるため、モデラーはMMMができることとできないことについて理解しておくことが重要です。モデリングプロセスの不確実性を知ったうえで、モデラーとエンドユーザーが、透明性を担保しながら意思決定に繋げる必要があります。できることならば、エンドユーザーも、モデル選択プロセスや推定方法について知ったうえで、不確実性について議論できた方がよいでしょう。
論文を読んだ所感
MMMの概要や近況を知るには、良い論文だったように思います。数式はほぼ記載がない論文ですので、英語が読める方であれば気軽に読めると思います。日本語だと、博報堂さんから出ている論文も、MMMの近況が整理されていて良いですので、こちらも是非読んでみてください。
Google, Meta, Uber, など、様々な企業からオープンソースのMMMが公開されていますが、結局は自信で作ったベイズ推定ベースのMMMが一番柔軟で使いやすいです。MMMが民主化されても、結局は分析リテラシーをもったアナリストによる意思決定のサポートがかなり重要だと感じています。
最後は余談ですが、MMMには、"Marketing Mix Modeling" という記載と、"Media Mix Modeling" という記載があるように思います。個人的には、MMMはMedia効果の検証に留まらず、プロモーションや店頭活動も含めた広義のMarketingに活かすべきだと考えているため、"Marketing Mix Modeling" という名前の方が好きです。
参考文献
・マーケティング・サイエンスにおける個票データの課題とMarketing Mix Modeling の「再発見」
・Bayesian Time Varying Coefficient Model with Applications to Marketing Mix Modeling
・Bias Correction For Paid Search In Media Mix Modeling
・Chan, D., & Perry, M. (2017). Challenges and opportunities in media mix modeling.
・Vaver, J., & Zhang, S. S. H. (2017). Introduction to the Aggregate Marketing System Simulator.
- * 「独立 = 相関が小さい」ではないですが、MMMの文脈ではこの解釈で良いと思います。 ↩︎