Ridge, LASSO回帰の罰則パラメータはサンプルサイズが大きくなるとどうなるか
線型回帰モデルに対する正則化は、あえて回帰係数にバイアスを持たせることで汎化性能を高めたり、多重共線性の問題を回避したりすることができる技術です。正則化を用いる場合、最小化する損失関数は以下の形になります。
$$\frac{1}{n}\|\boldsymbol{y} – \boldsymbol{X}\boldsymbol{\beta}\|_2^2 + p_{\lambda}(\boldsymbol{\beta})$$
\(\boldsymbol{y}\)は\(n\)個の要素を持つ目的変数値のベクトル、\(\boldsymbol{X}\)は\(n \times p\)の計画行列(特徴量の行列)、\(\boldsymbol{\beta}\)は\(p + 1\)個の要素を持つ偏回帰係数ベクトルです。
\(p_{\lambda}(\boldsymbol{\beta})\)は正則化項とよばれ、罰則パラメータλをハイパーパラメータとしてもつ\(\boldsymbol{\beta}\)の関数であり、この関数の設計次第で様々なモデルを実現できます。
例えば、\(p_{\lambda}(\boldsymbol{\beta}) = |\boldsymbol{\beta}|_1 = \sum_{i=1}^p{|\beta_i|}\)とすればLASSO(L1正則化)、\(p_{\lambda}(\boldsymbol{\beta}) = \|\boldsymbol{\beta}\|_2^2 = \sum_{i=1}^p{\beta_i^2}\)とすればRidge(L2正則化)となります。
正則化は\(\lambda\)が大きければ強く、小さければ弱く働き、例えばLASSOの場合だと\(\lambda\)を大きくすればより多くの回帰係数が0となります。\(\lambda\)は解析者が決定する必要があり、交差検証(クロスバリデーション、以降CVと書きます)や情報量規準を用いて決められることが多いです。
冒頭でも述べた通り正則化はバイアスを持たせる手法なので、当然推定される係数は真の値とはズレます。ですが、損失関数を見ると、サンプルサイズが大きい場合は\(\lambda\)が0に張り付いて、実質正則化なしの線形回帰になるのではという想いも拭えません。
ということで、この記事では\(\lambda\)をCVで決定する際、サンプルサイズを徐々に増やすとどのような値に決定される傾向にあるか、をシミュレーションで検証していきます。
実験の設定
Ridge, LASSOの2つのモデルを使って、人工的に生成したデータに対して回帰モデルを推定します。特徴量は「\(y\)と直接関係のある変数のみ」「\(y\)と直接関係のある変数と無関係な変数」の2パターンを使い、それぞれの設定で異なるサンプルサイズごとに5分割CVを使って\(\lambda\)を決定します。なお、\(\lambda\)の調節範囲は\([0, e^5]\)とします。
また、それぞれのサンプルサイズで複数回実験を行い、決定された\(\lambda\)の平均値と標準誤差を見て考察を進めます。
データの具体的な作成手順は次のとおりです。
- 真の回帰係数\(\boldsymbol{\beta}_{pop}\)を決定
- 母集団として、\(10000 \times 10\)の計画行列\(\boldsymbol{X}_{pop}\)を独立な正規分布により生成(無関係データも同様に生成)
- \(\boldsymbol{y} = \boldsymbol{X}_{pop} \boldsymbol{\beta}_{pop} + \boldsymbol{\epsilon}, \boldsymbol{\epsilon} \sim \mathcal{N}(\boldsymbol{0}, \sigma^2I_n)\)によって目的変数の母集団を計算
- 母集団から\(n\)個のデータをサンプリング
# 母集団のサンプルサイズと特徴量数
N = 1e4
p = 10
set.seed(0)
# 特徴量の母集団
X_pop = matrix(rnorm(N*p, mean=0, sd=1), nrow=N)
# 目的変数と無関係なデータ(ダミーデータ)
X_dummy = matrix(rnorm(N*5, mean=0, sd=1), nrow=N)
# 真の回帰係数をポアソン分布からランダムに生成して昇順に並べ替え
beta_pop = rpois(n=10, lambda=3) |> sort()
# 目的変数の母集団
y_pop = X_pop %*% beta_pop + rnorm(N, mean=0, sd=5)
# 母集団のフルデータとラベリング
df = data.frame(y = y_pop, X_pop, X_dummy)
colnames(df) = c('y', str_c('x', seq(1, 10, by=1)), str_c('dummy', seq(1, 5, by=1)))
# サンプリングする数のリストと罰則パラメータの探索範囲
N_list = floor(2^seq(3, 13, length.out=30))
lambda_range = c(0, exp(seq(-5, 5, length.out=99)))\(y\)と直接関係のある変数と無関係な変数を使用する場合
サンプリングするデータ数\(n\)は前述のコードの通り、\(2^i, i=3, 4, \ldots, 13\)とします。
N_ITER = 15
n_folds = 5
lam_mean_ridge = c()
lam_sd_ridge = c()
for (N in N_list) { # サンプリングする数についてのループ
lam_min = c()
for (iter in seq_len(N_ITER)) { # 乱数を変えてサンプリングするループ
set.seed(iter)
sample_index = sample(seq_len(nrow(df)), size=N, replace=FALSE)
df_sample = df[sample_index,]
vfold = vfold_cv(df_sample, v=n_folds)
mse_all = c()
for (i in seq_len(n_folds)) { # CV
train = analysis(vfold$splits[[i]])
test = assessment(vfold$splits[[i]])
X_train = select(train, -y)
y_train = pull(train, y)
models = apply(t(lambda_range), 2, function(lam) glmnet(x=X_train, y=y_train, alpha=0, lambda=lam))
pred = mapply(function(model) predict(model, newx=as.matrix(select(test, -y))), models)
if (is.null(dim(pred))) {
mse_fold = pred
} else {
mse_fold = apply(pred, 2, function(x) mean((pull(test, y) - x)^2))
}
mse_all = cbind(mse_all, mse_fold)
}
mse_mean = mse_all |> apply(1, mean)
bestlambda = lambda_range[which(mse_mean == min(mse_mean))]
lam_min = c(lam_min, bestlambda)
} # iteration
lam_mean_ridge = c(lam_mean_ridge, mean(lam_min))
lam_sd_ridge = c(lam_sd_ridge, sd(lam_min) / sqrt(N_ITER))
}LASSO もこれと同様行います(glmnet()でalpha=1にするだけ)。
Ridge, LASSO それぞれCVで選択された罰則パラメータ\(\lambda\)の平均と標準誤差を見てみます。
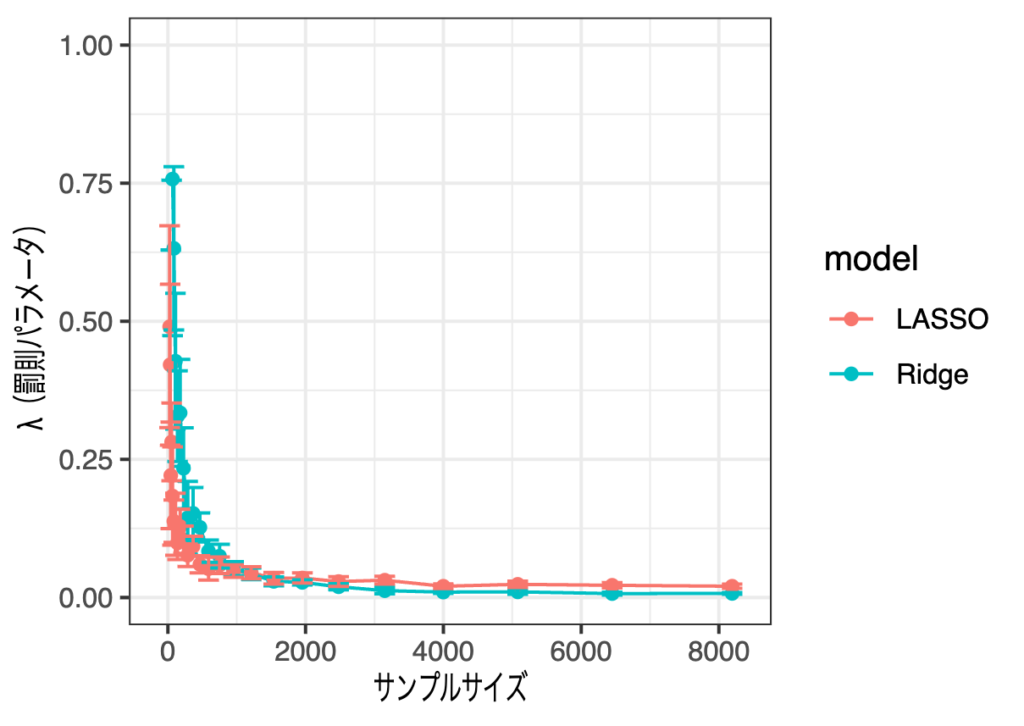
サンプルサイズが小さいときは罰則パラメータが非常に大きな値をとってしまうので、y軸の値の表示範囲を[0, 1]としています。こう見ると一応減少傾向にはありそうです。
もう少し拡大するために、表示範囲を[0, 0.1]にしてみます。
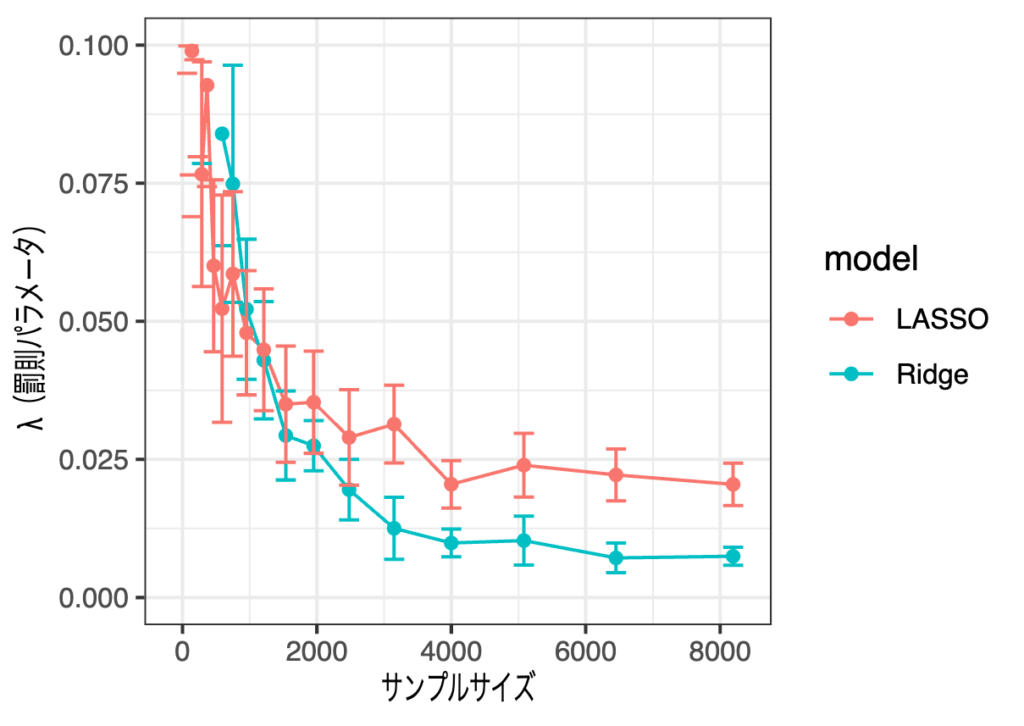
サンプルサイズが3,000くらいで減少率は頭打ちになってそうですが、サンプルサイズを増やせば罰則パラメータが小さくなり、正則化の効果が小さくなることが確認できます。結果として、サンプルサイズが大きい場合LASSOは全ての変数を選択し、係数も通常の線型回帰と似たものを出力していました。これはなかなか厄介な挙動ではないでしょうか。
\(y\)と直接関係のある変数のみを使用する場合
dfからX_dummyを除いたデータで同様の実験を行った結果がこちら。
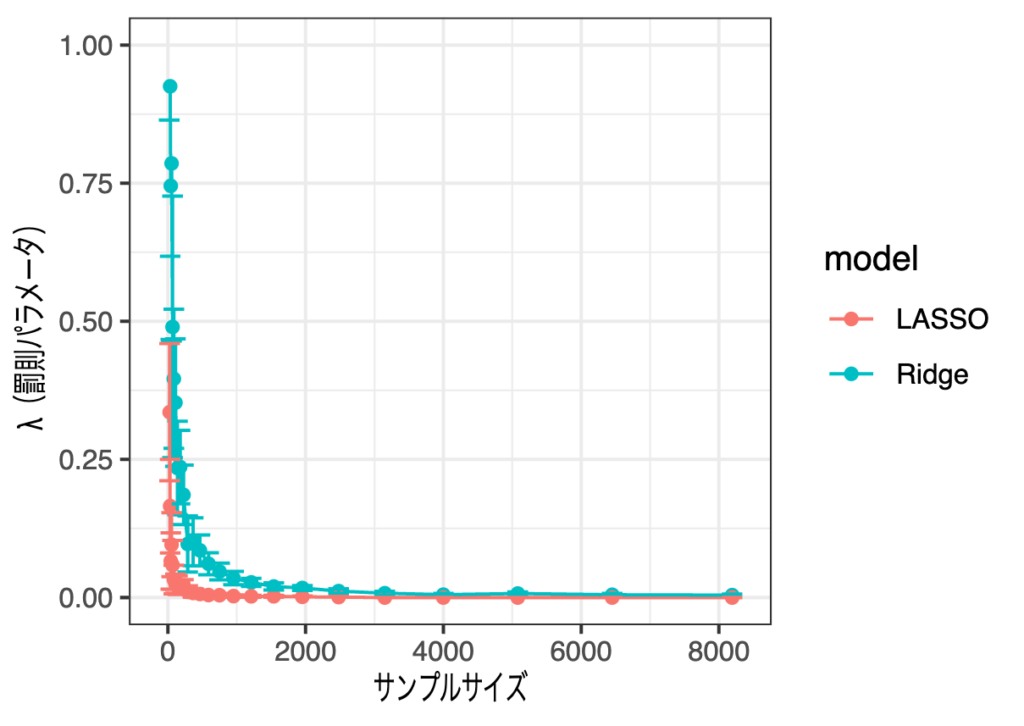
サンプルサイズが2,000弱で減少率は頭打ちになっている感じがしており、信頼区間はより狭くなっている感じがします。こちらもy軸の値を[0, 0.1]に絞ってみてみます。
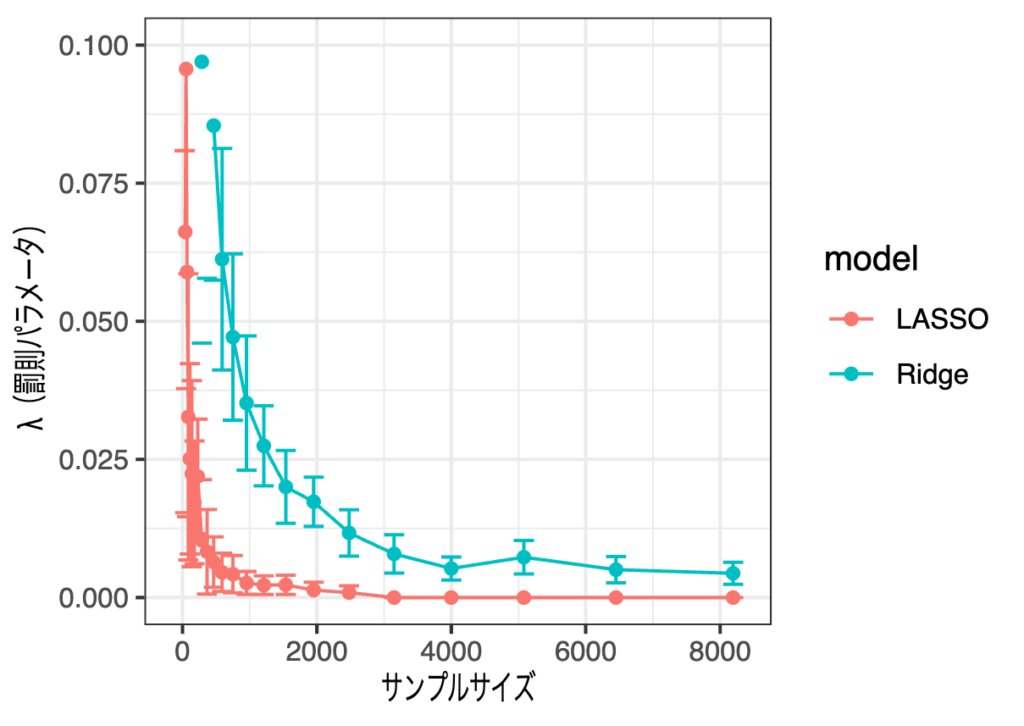
目的変数とは無関係の変数を入れた場合と比べると、選択される罰則パラメータの大小関係が逆になり、LASSOはより顕著に「いらない変数なんてありません!」と語るようになりました。どちらのモデルもより罰則が弱く(\(\lambda\)が小さく)なっており、これは全ての変数の影響がそれなりにあり縮小する必要がないためだと考えられます。LASSOに関してはサンプルサイズが3,000を超えたあたりからほぼ完全に0に張り付いています。
ここまでのまとめ
目的変数と直接関係のある変数のみを使う場合でも、無関係な変数を入れる場合でも、5分割CVによる罰則パラメータの決定では、サンプルサイズに反比例して罰則パラメータは小さくなることが確認されました。
これは、サンプルサイズを増やせば母集団に近づくため、損失関数の二乗和の部分をとにかく小さくした方が汎化性能も高くなるという結果によるものと考えられます。
概ね予想通りですが、一点気になるところがあります。
サンプルサイズを増やしたとしても、LASSOには無関係な変数の回帰係数は0と推定してほしいものです。
無関係な変数の数が多くてもサンプルサイズを増やせば選択されてしまうものなのでしょうか。ということで、より極端な状況で再度実験してみます。
\(y\)と無関係な変数の方が多い場合
\(y\)と関係あるものから1つ、無関係なもの全ての合計6つの変数を使った回帰を行います。結果は次のとおりです。
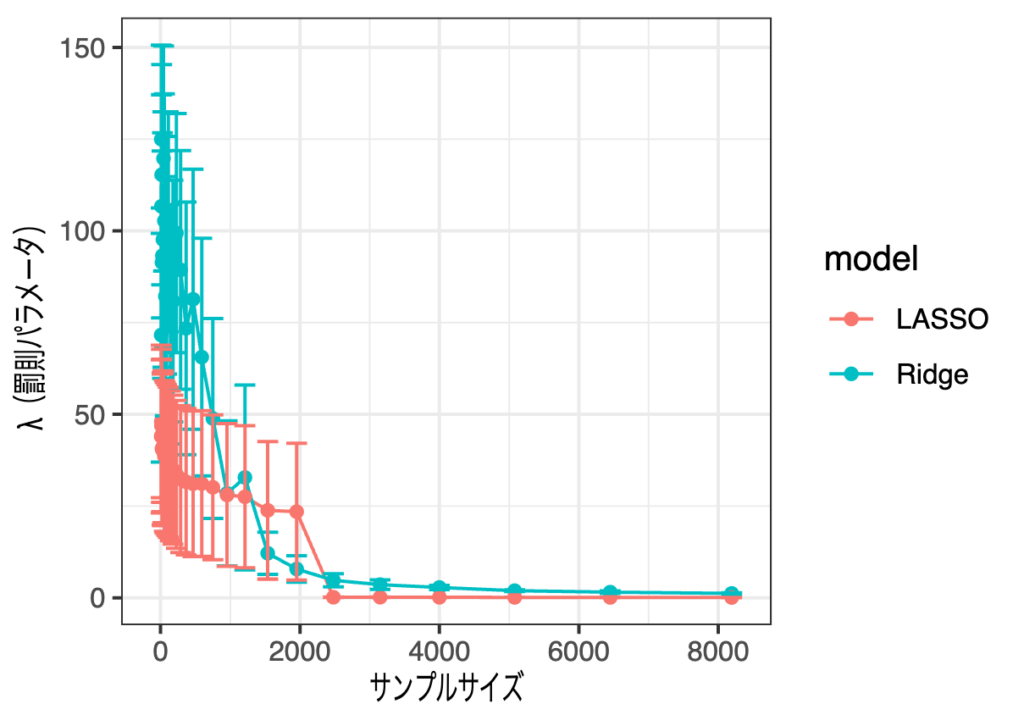
先ほどとは異なり、y軸の範囲を絞っていません。さすがにこれまでよりはサンプルサイズが大きくとも罰則を聞かせている様子です。もう少し拡大してみましょう。
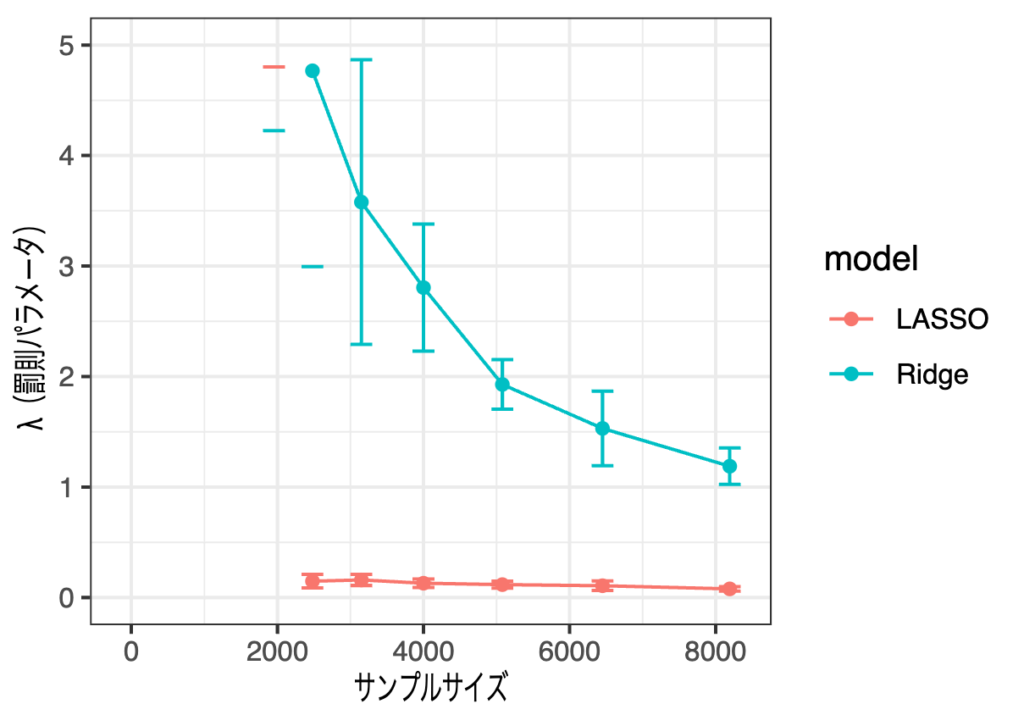
Ridgeはそれなりに罰則をかけているように見えますが、実は推定される係数を見るとそれほど0に縮小できていません。LASSOもこの程度の罰則では全ての変数を選択してしまってます。
限定的な設定ではありますが、これらの結果を信じるなら、LASSOを使って「全て選択されたので全て関係してます」とは言えそうにありません。選択されたとしても標準偏回帰係数が小さい場合は注意が必要だと感じました。