機械学習を使って中古車をお得に買いたい(Pycaret を使った価格予測と解釈)
友人A「MINI CROSSOVER をお得に買いたいんだけど、 AI でなんとかならない?」
なんとかしましょう。
作戦は
- カーセンサーで取引されている MINI CROSSOVER(中古車)の価格やモデル情報を取得
- 価格を予測する機械学習モデルを作成
- モデルの予測値を大幅に下回る車を”お得(割安)”と判断し、購入を検討する
です。
なお、これに落ち着いた経緯を FAQ 形式で説明すると以下のようになります。
- なんでカーセンサー? → MINI CROSSOVER の件数が多い、かつサイト違いによる情報の差を無くすため。
- 安い順に並べ替えれば? → 目的は安いものを買うではなく、”お得に”買うことです。そのため、なんらかの基準で"お得"を定義する必要があります。
- 散布図とか見れば、どの要素が高い(低い)なら安くなるとかわかるんじゃないの? → おそらく複雑であろう構造を単相関関係で近似(モデル化)するのは無理があるので、多変量を使った予測を行います。
- 「〇〇が起こると and/or 時間経つと将来安くなる」みたいな予測の方が使い勝手良いのでは? → それを実現するデータを収集するのが難しいです。
- 予測モデルを推定するなら、目的以外の車種も加えた方がいいんじゃないの? → 確かに、ある車種に対する予測しか行わないという目的だとしても、データを増やせば何らかの共通する構造をより正確に推定できる可能性はあります。しかし、今回は目的車種のデータ数が>1,000で特徴量数も10個ほどだったので、他の車種を加えることは余計な汎化性能を持たせることになると考え、除外しました。
- ”お得”の定義の理由は? → モデルが全体の傾向や本質的な関係を捉えられているのであれば、予測値を大幅に下回る車種はデータに現れない安い理由がある、つまりお得である可能性がある、という感じです。ただ、もちろんこれは「実は壊れてる部品があるけど公表されていない」というリスクとも解釈できますが、今回はお得だと信じることにします。
ちなみにこんな車です。

かっこいいですね。で、お値段はというと2023年3月時点で、最も安価な MINI COOPER D でメーカー小売希望価格が4,290,000~円、一番高い COOPER SD ALL4 で5,120,000円です。なお、中古 CROSSOVER の取引価格の分布はこんな感じです。
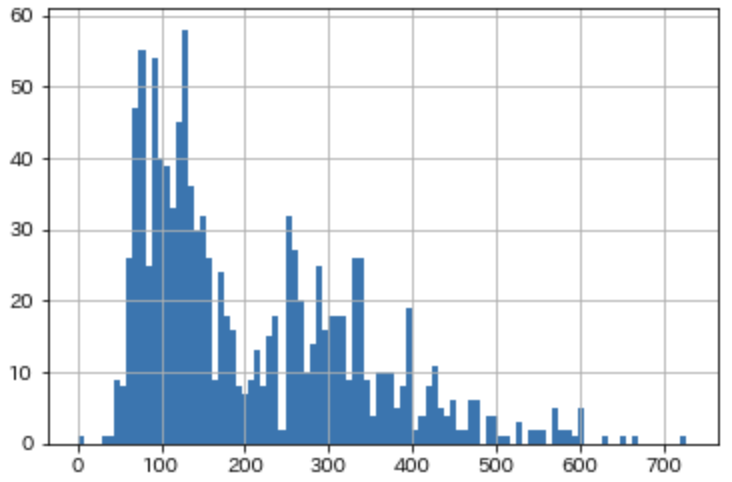
300万を切っているものもありますが、大体は古い年式(2010年生産など)だったり、修復歴があるものです。2020年以降のモデルに限定すると、こんな感じになります。
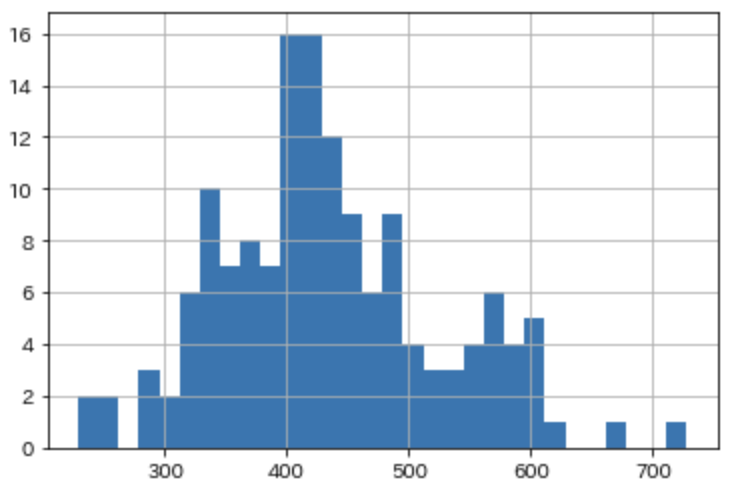
400万円付近にデータが集まっているようです。中古車でこのレベルですから決して安くはないと思います、何とかお得なものを探っていきましょう。
データ
カーセンサーの中古車データを収集します。データ収集に関しては Python によるスクレイピング&機械学習の本を参考にしました。
メーカーごとの中古車情報のページにいくと、以下のようなレイアウトのページに辿り着きます。
車名をクリックするとより詳細な情報が得られるんですが、今回は簡易的な分析 & サイト負荷を勘案して、こちらに移ってる情報のみを取得することにしました。
前処理など
以下の処理をしてます。他にも表記揺れへの対応など細かいことはやってますが、特に凝ったことはやってないです。
- 「排気量」はカテゴリとして扱う
- 年式を「生産されてから今までの年数」に変換(冗長な変換ですが、結果の解釈がしやすいので)
- 「車検までの日数」という変数を作成。なお、車検無しの場合はデータ収集日を車検日とする
- 「地域」はカテゴリ数が多いので、頻度を新たな特徴量とする
価格には「取引価格」と「総額」がありますが、「総額」を持たないサンプルが多数あったため、最終的に予測対象とするのは「取引価格」としました。
Pycaret を使って予測モデル推定
コードは長くなるので、要点だけ載せます。Pycaret は特徴量エンジニアリングの手法もたくさんあり非常に簡単に高い精度のモデルを自動で推定できてとても便利です。
まず、pycaret で扱うデータを読み込ませ、モデリングの準備をします。
from pycaret.regression import *
setting = setup(
data=df, target='y',
numeric_features=numerical_feature, categorical_features=categorical_feature,
high_cardinality_features=['region'], high_cardinality_method='frequency',
data_split_stratify=['isRepaired'],
silent=True, session_id=1)数値データとして扱いたい変数は numerical_feature に、カテゴリカルデータとして扱いたい変数は categorical_feature にリストで格納しておきます。
high_cardinality_features のところは「前処理」の部分で述べた、販売地域に対する数量化処理(カテゴリカル変数→頻度で数値に)です。
モデリングの準備ができたので、どんなモデルが良いフィッティングを出しそうかのあたりをつけるため、さまざまなモデルをデフォルトパラメータで学習し、CV での平均スコアを比較します。
compare_models(sort='MAPE')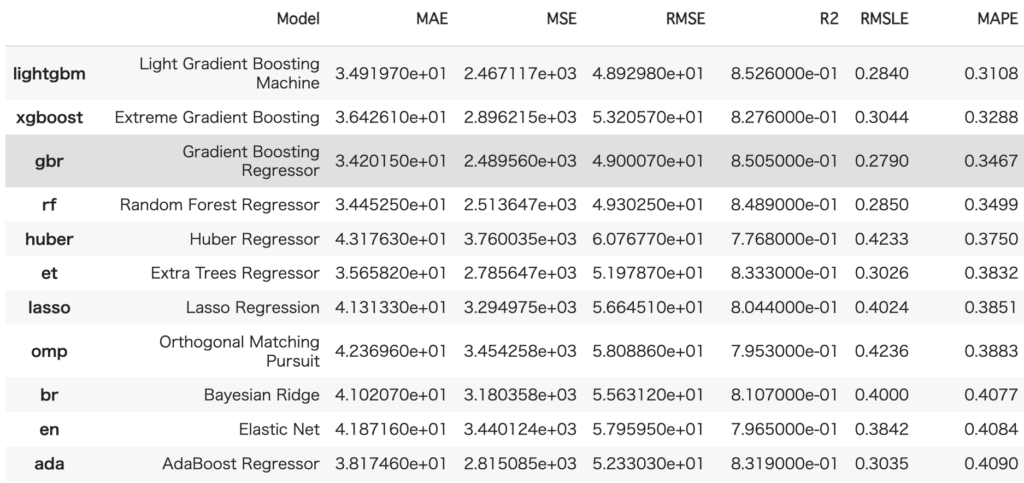
こんな出力がされます、便利ですね。MAPE が一番良かった lightgbm を使うことにします。
使うモデルが決まったので、適当にチューニングして最終的に解釈するためのモデルを推定します。
model = create_model('lightgbm')
model_tuned = tune_model(
model,
optimize='MAPE',
n_iter=150,
choose_better=True)choose_better=True によって、チューニングによって CV に対する精度の平均が悪くなったら、チューニング前のモデルを返すようにしています。n_iter はデフォルトのハイパラチューニング方法である RandomGridSearch の繰り返し回数です。これに関しては、適切なライブラリをインストールして search_library 引数を指定することで hyperopt なり optuna なり使えます。
実は Pycaret では事前にテストデータ(学習に一切関与していないデータ)を別にとっておいてあります。これに対するチューニング後のモデルの精度を比較してみましょう。
predict_model(model_tuned)
ドメインにもよりますが、決定係数が0.88、MAPEが0.18と、テストデータに対しても良好な精度を出せていることがわかります。
モデルの推定が終わったので、現在での最も良いハイパーパラメータを使い、別にとっておいたテストデータも含めてモデルを再学習し、"お得"な MINI CROSSOVER を探っていきたいと思います。
model_fin = finalize_model(model_tuned) # 全データを使って再学習(ハイパラはいじらない)モデルの予測値を大幅に下回る車(=お得車)を確認
再掲ですが、今回の分析では「精度が十分と思われるモデルを推定し、そのモデルの予測値を大幅に下回る車をお得とする」方針です。
とりあえず、予測を100万円以上下回る、非常に大胆に言い換えれば「普通なら500万する車がなぜか400万以下で売られている」車をフィルタしてみると、こちらの1件のみがヒットしました。

(ちなみに、予測時点では価格は389万円でしたが、さらに値下げされているようでした)
予測値は515.74万円。その差は(分析時点で)約126万円です。大幅にお得感が出ていますが、本当にお得かどうかは豊富な経験や相場観をもとに実物を確認しないとわかりません。とりあえず、モデルに理由を語らせてみましょう。方法はいろいろありますが、今回は SHAP 値を使って確認します。SHAP(SHapley Additive exPlanation) 値は「ある1サンプルに対する予測値を変数別の寄与に分解したもの」です、つまりある予測値がどのような変数を参考に構成されたかを確認できます。
こちらの車種の予測の SHAP 値は以下の通りです。

赤だったら予測値が高く、青だったら低くなっている要因ということです。
これを見ると、「平均と比べて高くなる要素ばかりだよ!生産されてから2年しか経ってない!しかも1.2万キロしか走ってないし、車検までの期間も十分あって排気量も高いよ!」というふうに伝えてくれていますね。では、生産年から2年以内、かつ走行距離が1.2万キロ以内かつ排気量が2,000の車に限定して、分布をみてみます。
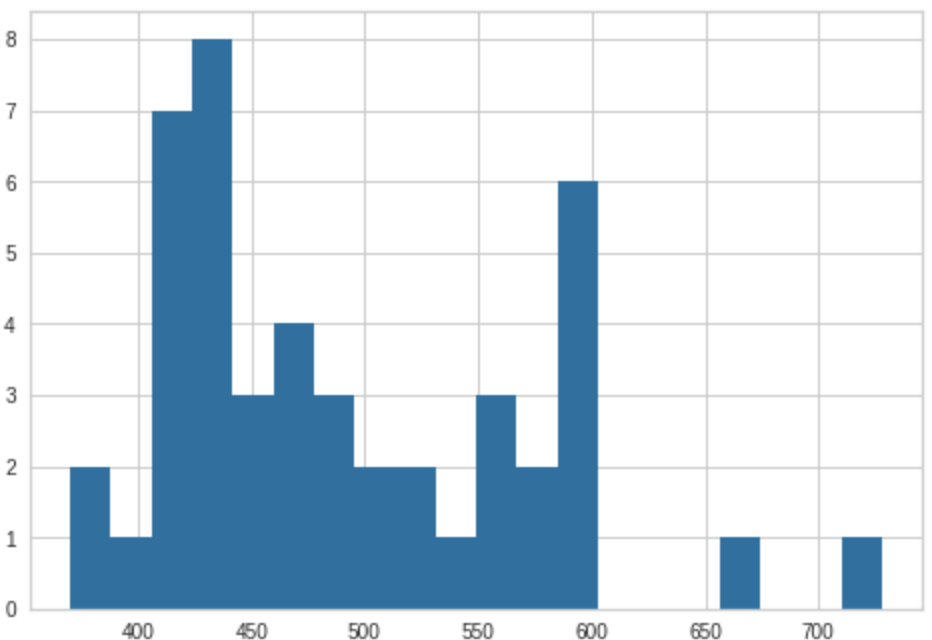
確かに400以下の時点で激レアですね。
みた感じ、修復歴があるなどの理由もなく、本当にお得なのかもしれません。
今回は閾値を100万円としましたが、当然任意の価格でフィルタすることができますし、それによってより多くの候補を抽出することもできます。
ということでまとめると、
作成したモデルの予測値を約126万円も下回る価格で取引されている MINI COOPER D があり、SHAP 値(予測の理由)的にも確かに高くなりそうに思えたので、本当にお得かもしれない。
最後に
データの更新に関しては、今までのデータと合わせたくなりますが、その時期によるトレンドみたいなものもある可能性があるので、ある時点で一括でデータを更新する、という運用が無難だと思います。
適当な前処理とモデリングでここまでの精度が出るのは逆にこの手法の改善幅を示唆しているのかなと思います。もっと詳しく!って方はコメントください。