縮小推定は本当に縮小するのか
Lasso、Ridge などで知られる正則化を使ったモデル推定は「縮小推定」ともよばれます。なぜこうよばれているかというと、推定パラメータがある値に近くなりやすいように推定する手法だからであり、Lasso と Ridge に関してはこの「ある値」とは0を指します。
Ridge 回帰における最小化問題は、目的変数ベクトル \(\mathbf{y}\)、計画行列 \(\mathbf{X}\)、偏回帰係数ベクトル \(\boldsymbol{\beta}\) を使って以下のように表されます。
$$\underset{\boldsymbol{\beta}}{\text{min}} ||\mathbf{y} – \mathbf{X}\boldsymbol{\beta}||_2^2 \quad \text{subject to} ||\boldsymbol{\beta}||_2^2 \leq t$$
ここで、Lasso なら制約条件がL1ノルム(\(||\boldsymbol{\beta}||_1\))となります。確かに、パラメータのノルムが \(t(>0)\) 以下という制約がかかっているため、制約無しよりは絶対値が小さくなるような推定がされそうです。
またベイズ推定の視点で見ると、Lasso と Ridge は推定パラメータの事前分布にそれぞれラプラス分布、正規分布を仮定した最大事後確率(MAP)推定です。二つの分布の形は以下の通りです。
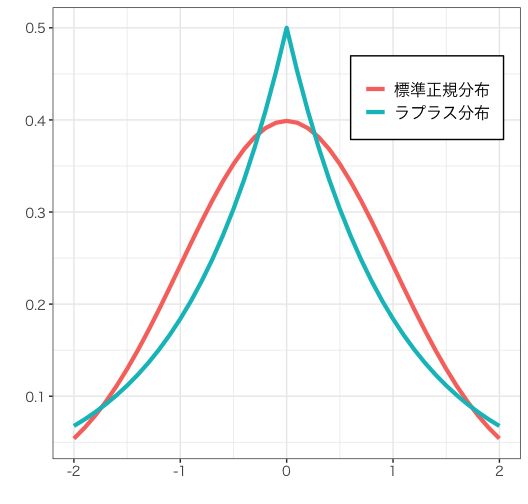
事前分布は0のあたりの密度が高いため、やはり推定パラメータは0に近づくようなバイアスを持つはずです。また、分布の形状からも伺えるように、Lasso はより強く0に近づけそうであることがわかります。
Lasso、Ridge における縮小推定によりパラメータが0に近づくように推定されそうなことはわかりました。では、常に制約なしの回帰(OLS 推定)よりも絶対値が0に近いような推定になるのか、またどれくらい0に近づくように推定されるのかを確認してみます。
Lasso, Ridge, 制約なし回帰(lm と表記)の回帰係数を比較
実データで確認
ボストンの住宅価格データを使ってモデル推定し、偏回帰係数の絶対値を比較することで縮小推定されているかを確認します。データの内容についてはこちらをご参照ください。
なお、回帰係数を比べやすくするため、データはあらかじめ平均0分散1に標準化しています。また、今回は縮小推定されるかのみに関心があるため、特にデータを訓練・テストと分割したりしません。
サンプルサイズ、罰則パラメータをそれぞれ2通り用意して、計4つの設定でモデルごとの回帰係数の絶対値を折れ線グラフで比べたものがこちらです。
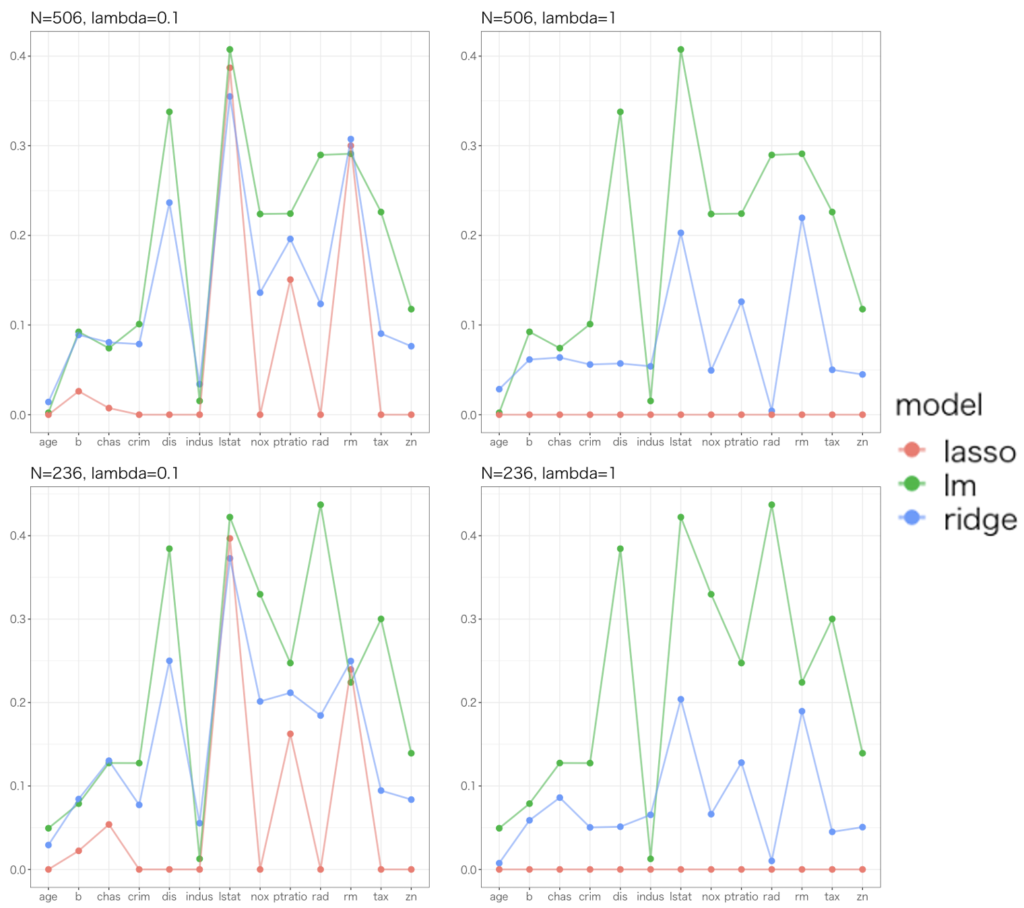
大体は「制約無し>Ridge>Lasso」という具合で絶対値が小さく推定され、罰則パラメータを大きくするとさらに小さく推定されるという、罰則の狙い通りの傾向が伺えます。一方で、indus(町あたりの非小売業の割合), rm(1戸あたりの平均部屋数) の回帰係数に関しては僅差ではありますが Ridge, Lasso の方が大きな値を推定していることがわかります。
この時点で、「常に制約なしの推定値よりも絶対値が0に近いような推定」になるわけではないことが確認できました。
人工データでも確認してみる
次のような設定でデータを作ります。
$$x_{1,i} \sim \mathcal{N}(0,1^2), \quad x_{2,i} \sim \mathcal{N}(0,1^2), $$
$$y_i \sim \mathcal{N}(0.2x_{1,i} – 0.2x_{2,i}, 1^2), \quad i = 1,\ldots, N$$
日本語でいうと、\(x_1\)、\(x_2\)を正規乱数で生成して、\(x_1\)に0.2、\(x_2\)に-0.2をかけて足したものに正規乱数を加えることで \(y\) を生成しています。
サンプルサイズを50, 100, 500とし、サンプル数はいずれも500で同様の実験を行い、偏回帰係数の分布や OLS 推定量より小さくならなかった回数を見てみます。つまり、サンプルサイズ \(N\) で回帰係数を求めるのを初期値違いで500回繰り返し、500通りの回帰係数を計算します。
以下はサンプルサイズ500の結果です。
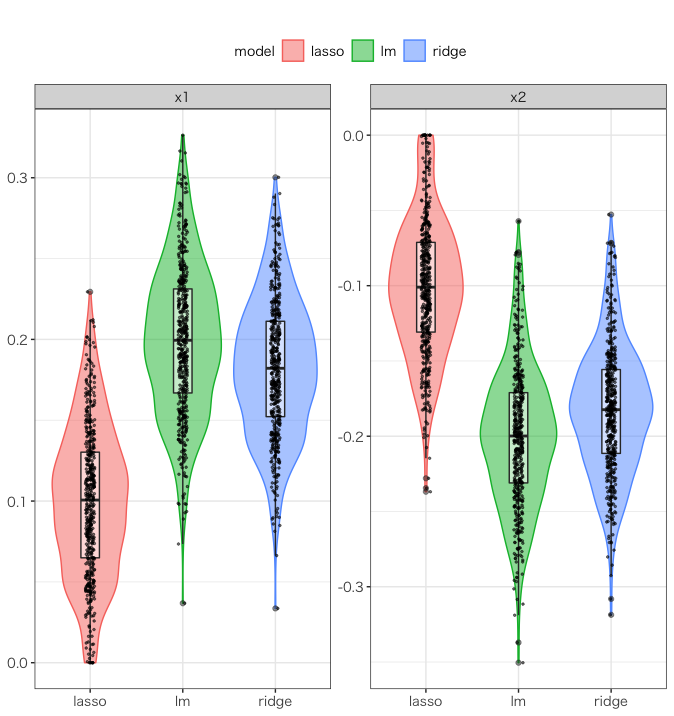
これはバイオリンプロット、箱髭図、横にバラつかせたサンプル点の三つを重ね書きしたものです。
また、モデル別回帰係数の平均値と標準偏差は以下の通りです。\(x_j\) の偏回帰係数を \(\beta_j\) と表記します。
| \(\beta_1\) の平均 | \(\beta_1\) の標準偏差 | \(\beta_2\) の平均 | \(\beta_2\) の標準偏差 | |
| OLS | 0.199 | 0.047 | -0.200 | 0.047 |
| Ridge | 0.182 | 0.043 | -0.183 | 0.043 |
| Lasso | 0.100 | 0.046 | -0.101 | 0.046 |
これらをみると、このデータセットの場合は Ridge と OLS を比較するとそれほど顕著に回帰係数の分布が異なっているようには見えません。しかし、Ridge, Lasso は OLS に比べて平均値が0に近く、標準偏差も小さいことがわかり、縮小推定していることが伺えます。また、これらの傾向は \(N=50, 100\) でも同様にみられました。
偏回帰係数の絶対値の大きさが Ridge > OLS となる回数を数えると、以下のような結果となりました。
| サンプルサイズ | \(\beta_1\) | \(\beta_2\) |
| 50 | 17 | 11 |
| 100 | 3 | 6 |
| 500 | 0 | 0 |
サンプルサイズが小さいほど、OLS 推定による偏回帰係数の方が大きくなることが起きやすいようです(と言っても、試行回数の2%ほどですが)。
数式を見ると
人工データの特徴量を2変数にしたのには訳があって、2変数だと数式として表しやすいためです。実際、簡単のため変数は全て平均0分散1に標準化されているとして、\(x_1\) の偏回帰係数の OLS 推定量と Ridge 推定量は次のように表せます。
$$\beta_{1,\text{OLS}} = \frac{\sigma_{x_1y} – \sigma_{x_2y}\sigma_{x_1x_2}}{1 – \sigma_{x_1x_2}}$$
$$\beta_{1,\text{Ridge}} = \frac{(1 + \lambda)\sigma_{x_1y} – \sigma_{x_2y}\sigma_{x_1x_2}}{(1+\lambda)^2 – \sigma_{x_1x_2}}$$
ここで、\(\sigma_{xy}\) は、\(x\) と \(y\) との共分散(標準化されているので相関係数)です。
この式から、\(n\lambda\) の影響が他の共分散のスケールと比べて小さいようだと、OLS 推定量の方が小さくなるという現象が起きるようです。また、これを \(\lambda\) について微分して \(\lambda=0\) とおき、それが非負となる条件を求めればより詳細に縮小が起こらない場合を確認することができます。
結論
「必ずしも縮小する(0に近くなる)わけではない」