R で可視化〜ヒートマップ〜
ggplot によるヒートマップの魅力を存分に伝えていこうと思います。
データは Boston の住宅価格データを使います。
ヒートマップとは
ある値の高低を色に反映させて図示したものです、例えばこんな図です(架空データ)。
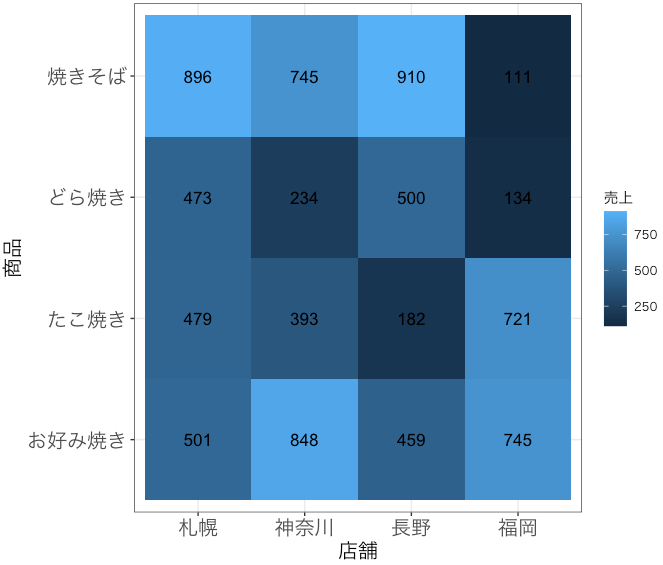
いわゆるピボットテーブルや、相関係数など、2つの尺度があってそれに対応する値を確認したいときに便利です。この例だと「焼きそばは全体的に売上がいいのに福岡だけ全然売れてないな、でも福岡はたこ焼きが他よりだいぶ売れてるな」と、色ですぐに判断することができます。
また、この例では軸にカテゴリを設定していますが、最初に述べた通り「ある値の高低を色に反映させて図示」するものなので、軸が連続値だろうとヒートマップはかけます(等高線とヒートマップを合わせた図はよく見かけます)。
可視化
今回は、ボストンの住宅価格を分析する過程の随所にヒートマップを登場させながら使い方を紹介します。
まずはデータを読み込んで中身を覗きます。
# スタメンパッケージ
library(dplyr); library(tidyverse)
library(ggplot2); library(mlbench)
# ボストンの住宅価格データ
data(BostonHousing)
data = as_tibble(BostonHousing)
print(data, n = 3, width = Inf)# A tibble: 506 x 14
crim zn indus chas nox rm age dis rad tax ptratio b lstat medv
<dbl> <dbl> <dbl> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.00632 18 2.31 0 0.538 6.58 65.2 4.09 1 296 15.3 397. 4.98 24
2 0.0273 0 7.07 0 0.469 6.42 78.9 4.97 2 242 17.8 397. 9.14 21.6
3 0.0273 0 7.07 0 0.469 7.18 61.1 4.97 2 242 17.8 393. 4.03 34.7
# … with 503 more rowsこの内、目的変数を medv とし、EDA、予測モデル推定にヒートマップを活用していきます。
相関係数
data$chas = as.numeric(data$chas) # 相関係数を計算するために連続値として型変換
library(reshape2)
cor_melt = cor(data) %>% melt() # 変数1、変数2、値 という縦長形式に変換
ggplot(data = cor_melt, aes(x = Var1, y = Var2, fill = value)) +
geom_tile() + # これでヒートマップ出力
geom_text(aes(label = round(value, 2)), show.legend = FALSE)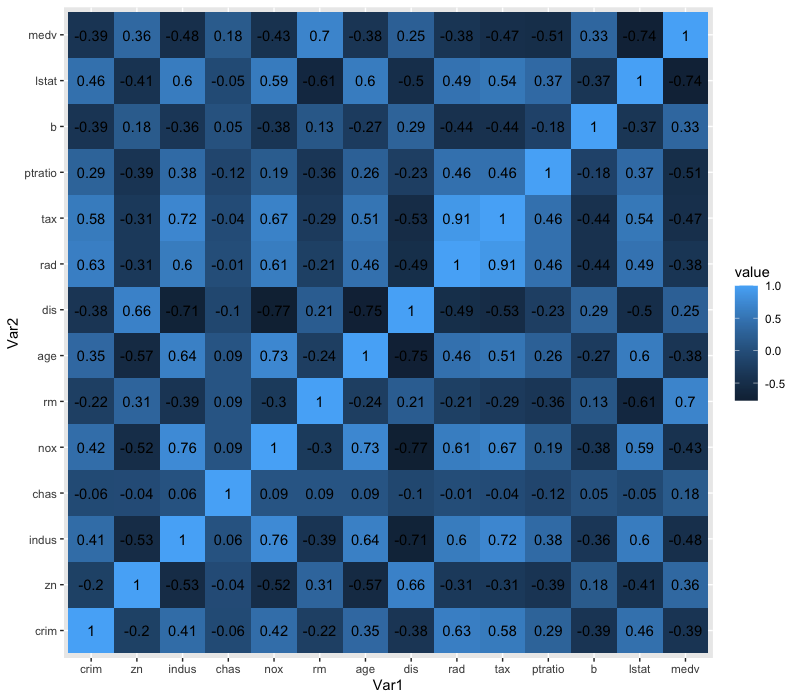
数字の羅列より遥かに良いですね。例えば、lstat(その地域における低所得者人口の割合)と medv(その地域の持ち家の価格の中央値)は比較的強い負の相関があること、rm(平均部屋数)とは正の相関があることがわかります。
ただ、これだとなんらかの基準があった場合にその境界が分かりにくいため、色を3段階にしてグラデーションさせてみます。今回は、無相関を表す0を基準とします(midpoint = 0)
ggplot(data = cor_melt, aes(x = Var1, y = Var2, fill = value)) +
geom_tile() +
geom_text(aes(label = round(value, 2)), show.legend = FALSE) +
scale_fill_gradient2(low = "blue", mid = "white", high = "red", midpoint = 0) # ココ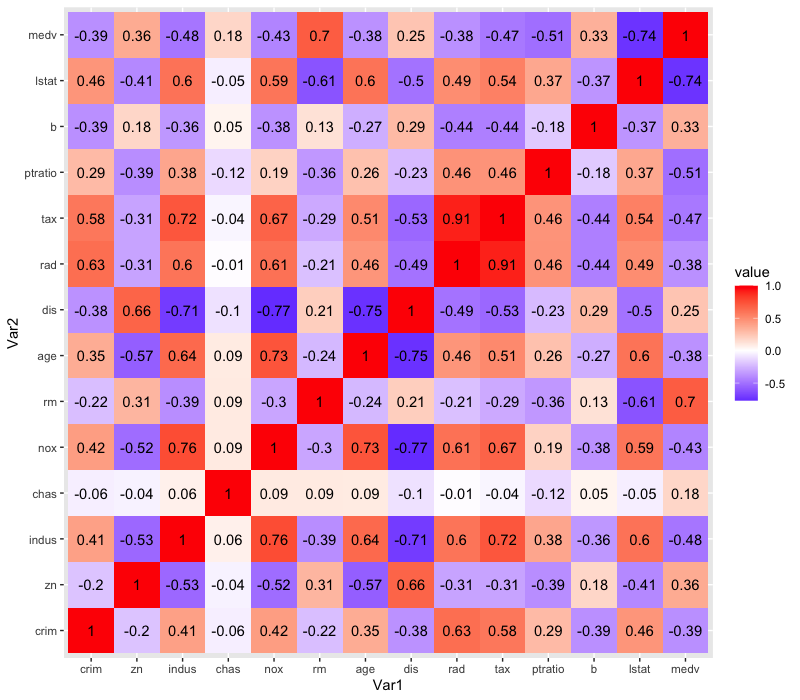
だいぶ良いですね。これなら、「負の相関」「無相関」「正の相関」が視覚的にすぐ確認できます。
ついでに偏相関係数も。
library(ppcor)
pcor_melt = pcor(data)$estimate %>% melt()
ggplot(data = pcor_melt, aes(x = Var1, y = Var2, fill = value)) +
geom_tile() +
geom_text(aes(label = round(value, 2)), show.legend = FALSE) +
scale_fill_gradient2(low = "blue", mid = "white", high = "red", midpoint = 0)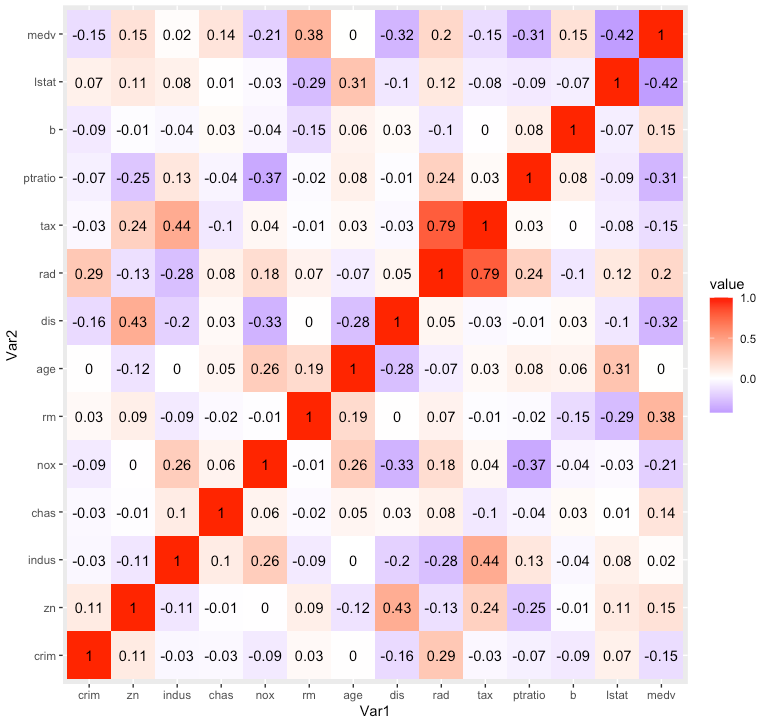
ppcor パッケージの pcor() 関数は有意確率やサンプルサイズなどもまとめてリストで返すので、pcor(data)$estimat として偏相関係数のみ取り出しています。相関係数と偏相関係数を比べると、indus や age と medv の係数の絶対値が大幅に減少していることから、他の変数で条件付けた場合は indus や age は medv とは関係ない可能性があり、線形重回帰分析をしたとしてもこのままでは有意な偏回帰係数とはならないだろうなと予想できます。
カテゴリの組み合わせに対する medv の値
最初の例で紹介した、ピボットテーブル的な表にヒートマップを導入する方法です。
ダミー変数の chas(チャールズ側が近くにあるか)と、ユニーク数が少ない rad(どれくらい高速道路にアクセスしやすいか)を軸にして medv をヒートマップ表示してみます。
一つデータを加工すべき点として、二つの軸の組み合わせが重複するとその分だけ medv の値も重複してしまうため、最初に chas と rad でグループ化して medv の平均を計算したデータを作ります。
pivot = data[,c("chas", "rad", "medv")] %>%
group_by(chas, rad) %>%
summarize(medv = mean(medv))
pivot A tibble: 15 x 3
# Groups: rad [9]
rad chas medv
<dbl> <dbl> <dbl>
1 1 1 23.0
2 1 2 50
3 2 1 26.8
4 3 1 27.9
5 3 2 28.0
6 4 1 21.0
7 4 2 25.8
8 5 1 25.5
9 5 2 27.5
10 6 1 21.0
11 7 1 27.1
12 8 1 31.5
13 8 2 26
14 24 1 15.4
15 24 2 31.4確かに chas と rad の組み合わせに重複がなくなっています、あとは相関係数と同様です。
ggplot(data = pivot, aes(x = chas, y = rad, fill = medv)) +
geom_tile() +
geom_text(aes(label = round(medv, 2)), show.legend = FALSE)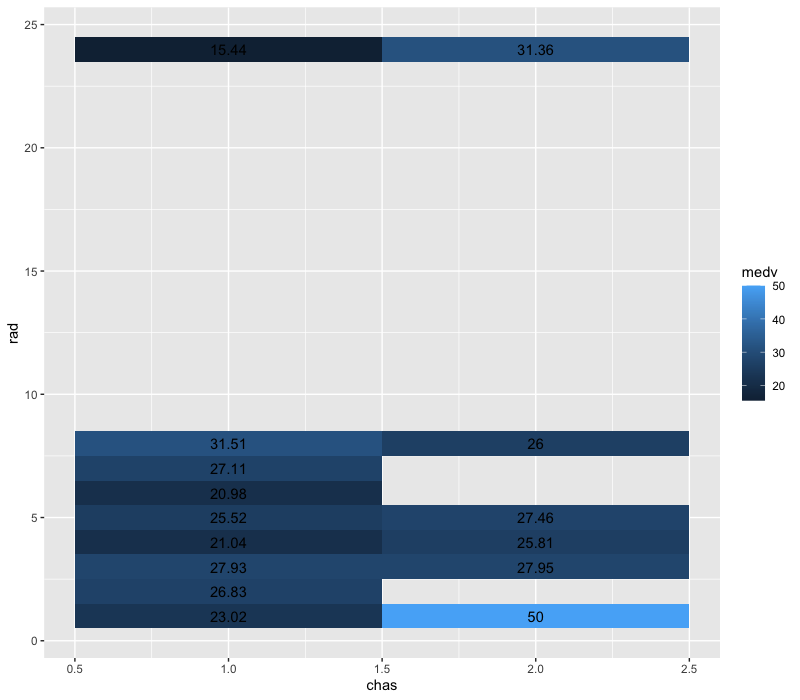
「川が近くにあると安くなる」という傾向は高速道路へのアクセスのよさで場合わけしてもあまり変わらなそうでが、「高速アクセスが良いかつ近くに川がない」「高速アクセスが悪いかつ近くに川がある」という部分は強い相乗効果があるようです(左上と右下)。
特徴量を2次元に圧縮し、2次元平面上にヒートマップ(投稿線図)
特徴量が似ているならを近くに配置されるようにサンプルを二次元座標上にマップし、そこに z 軸の値として medv をヒートマップで表します。この図は、例えば medv の高低に対する特徴量のパターンを考察することに役立ちます。
pca = prcomp(x = data[,-14], scale = TRUE) # 主成分分析
coordinate = tibble(pc1 = pca$x[,1], pc2 = pca$x[,2], medv = data$medv) # 第一、二主成分得点と medv からなるデータ
library(interp)
grid = with(coordinate, interp(pc1, pc2, medv, nx = 100, ny = 100)) # 等高線を書くために、z 軸の値に関して線形補完
z = grid$z
rownames(z) = grid$x
colnames(z) = grid$y
z_melt = melt(z)
ggplot(z_melt, aes(x = Var1, y = Var2)) +
geom_contour_filled(aes(z = value), bins = 6) +
geom_point(data = coordinate, aes(x = pc1, y = pc2))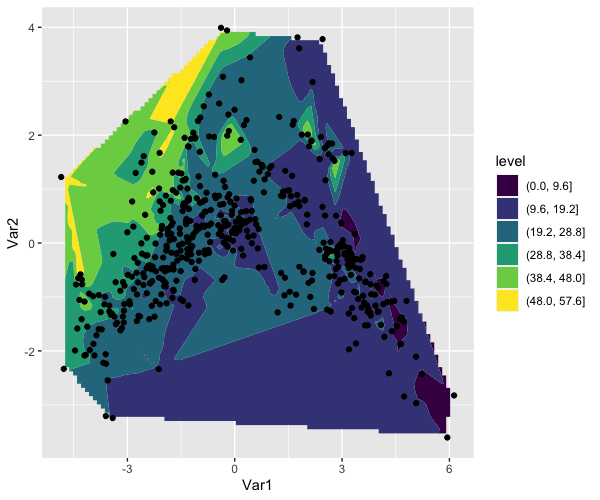
等高線図であればサンプルも表示させたいので、ここでは geom_tile() ではなく geom_contour_filled() を使ってます。
今回のデータの場合特に特徴的なグループはできませんでしたが、ヒートマップ(ここでは等高線図というべき?)の便利さはなんとなく伝わるのではないでしょうか。
予測モデル推定する際のパラメタチューニングに使う
予測モデルを推定して、パラメータチューニングする際にハイパーパラメータの組み合わせとバリデーションデータに対する予測精度をみて、どんな組み合わせが良さそうなのかを見た目でわかりやすいようにします。
今回はハイパーパラメータの組み合わせに対する予測精度(MAPE)をヒートマップで見ることが目的なので、データの分割方法は簡単に学習用とテスト用とします。
set.seed(0)
allocation = sample(c("train", "test"), size = nrow(data), replace = TRUE, prob = c(0.7,0.3))
# 学習用
train = data[allocation == "train",]
x_train = train[,-14] %>% as.matrix()
y_train = train$medv
# テスト用
test = data[allocation == "test",]
x_test = test[,-14] %>% as.matrix()
y_test = test$medv予測にはエラスティックネットと呼ばれる手法を使います。
エラスティックネットは Ridge のグループ効果と Lasso のスパース推定という性質を合わせたありがたい手法ですが、詳細については主旨ではないため割愛します。エラスティックネットを推定する際に最小化する目的関数を数式で表すとこんな感じです。
$$
\sum^N_i{l(y_i, x^\top_i\beta)} + \lambda[(1 – \alpha)||\beta||_2^2 + \alpha||\beta||_1]
$$
左が損失関数、右が正則化項です。この内、\(\lambda\) と \(\alpha\) の組み合わせに対するテストデータの予測精度を見ていきます。ちなみに、\(\alpha = 1\) で Lasso、\(\alpha = 0\) で Ridge になります。
library(glmnet)
alpha = seq(0, 1, length.out = 50)
lambda = seq(0, 1, length.out = 50)
result_all = tibble()
for (a in alpha) {
result = tibble()
for (l in lambda) {
model = glmnet(x = x_train, y = y_train, lambda = l, alpha = a)
pred = predict(model, newx = x_test)
mape = sum(abs((y_test - pred) / y_test)) / length(pred) * 100
result = rbind(result, tibble(lambda = l, alpha = a, mape = mape))
}
result_all = rbind(result_all, result)
}
ggplot(data = result_all, aes(x = lambda, y = alpha, fill = mape)) +
geom_tile()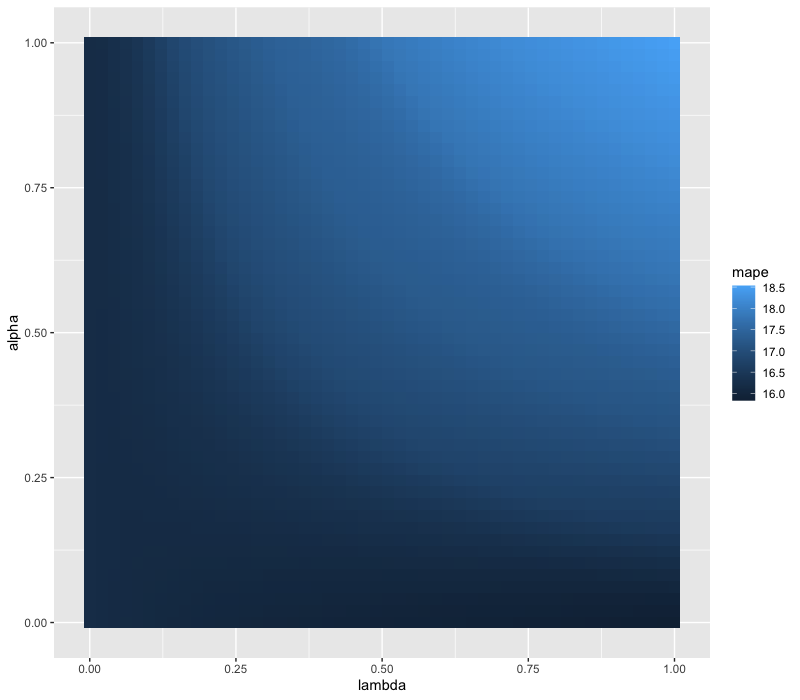
海の中のような美しい絵ができました。これを見ると、\(\alpha\) と \(\lambda\) の両方を高くする、つまりより厳しく変数選択をやろうとすると精度が悪くなり、\(\alpha\) を低くする(Ridge に近づける)のであれば罰則は弱くしないほうが精度が良くなりそうだということが確認できます。